
我已经编写了这个双缓冲区的实现:
// ping_pong_buffer.hpp
#include <vector>
#include <mutex>
#include <condition_variable>
template <typename T>
class ping_pong_buffer {
public:
using single_buffer_type = std::vector<T>;
using pointer = typename single_buffer_type::pointer;
using const_pointer = typename single_buffer_type::const_pointer;
ping_pong_buffer(std::size_t size)
: _read_buffer{ size }
, _read_valid{ false }
, _write_buffer{ size }
, _write_valid{ false } {}
const_pointer get_buffer_read() {
{
std::unique_lock<std::mutex> lk(_mtx);
_cv.wait(lk, [this] { return _read_valid; });
}
return _read_buffer.data();
}
void end_reading() {
{
std::lock_guard<std::mutex> lk(_mtx);
_read_valid = false;
}
_cv.notify_one();
}
pointer get_buffer_write() {
_write_valid = true;
return _write_buffer.data();
}
void end_writing() {
{
std::unique_lock<std::mutex> lk(_mtx);
_cv.wait(lk, [this] { return !_read_valid; });
std::swap(_read_buffer, _write_buffer);
std::swap(_read_valid, _write_valid);
}
_cv.notify_one();
}
private:
single_buffer_type _read_buffer;
bool _read_valid;
single_buffer_type _write_buffer;
bool _write_valid;
mutable std::mutex _mtx;
mutable std::condition_variable _cv;
};
使用这个只执行交换的虚拟测试,它在Linux上的性能比视窗差20倍:
#include <thread>
#include <iostream>
#include <chrono>
#include "ping_pong_buffer.hpp"
constexpr std::size_t n = 100000;
int main() {
ping_pong_buffer<std::size_t> ppb(1);
std::thread producer([&ppb] {
for (std::size_t i = 0; i < n; ++i) {
auto p = ppb.get_buffer_write();
p[0] = i;
ppb.end_writing();
}
});
const auto t_begin = std::chrono::steady_clock::now();
for (;;) {
auto p = ppb.get_buffer_read();
if (p[0] == n - 1)
break;
ppb.end_reading();
}
const auto t_end = std::chrono::steady_clock::now();
producer.join();
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(t_end - t_begin).count() << '\n';
return 0;
}
测试环境为:
-O3-pthread/O2你可以在这里找到代码在戈德波特,ASM输出GCC和VS2019与编译器标志实际使用。
这种巨大的差距在其他机器上也有发现,似乎是由于OS。
这可能是这种惊人差异的原因?
更新:
测试也在同一10700K的Linux上进行,仍然比视窗慢8倍。
-O3-pthread如果迭代次数增加10倍,我得到2900毫秒。
正如迈克·罗宾逊所回答的,这可能与Windows和Linux上不同的锁定实现有关。我们可以通过分析每个实现切换上下文的频率来快速了解该功能的开销。我可以做Linux配置文件,好奇是否有其他人可以尝试在Windows上进行配置文件。
我在Intel(R)Core(TM)i9-8950HKCPU@2.90GHz上运行Ubuntu 18.04CPU
我使用g-O3-pthread-g test. cpp-oping_pong编译,并记录了上下文如何使用以下命令切换:sudo perf记录-s-e sched:sched_switch-g--call-graph dwarf--./ping_pong我使用以下命令从perf计数中提取了一份报告:sudo perf报告-n--header--标准输入输出
报告很大,但我只对显示记录了大约200,000个上下文切换的这部分感兴趣:
# Total Lost Samples: 0
#
# Samples: 198K of event 'sched:sched_switch'
# Event count (approx.): 198860
#
我认为这表明性能非常差,因为在测试中,有n=100000项被推送
像这样大的问题可能与锁定的各自实现有关。分析器应该能够分解进程被迫等待的原因。这两个操作系统之间的锁语义学和特性完全不同。
正如@GandhiGandhiLinux回答的那样,我在视窗10上运行了同样的测量。
我使用Pix为在MSVC VS 2019上的x64 Release中运行的应用程序生成采样配置文件。对于这个采样配置文件,我过滤掉了2个用于争用的线程,显示为:
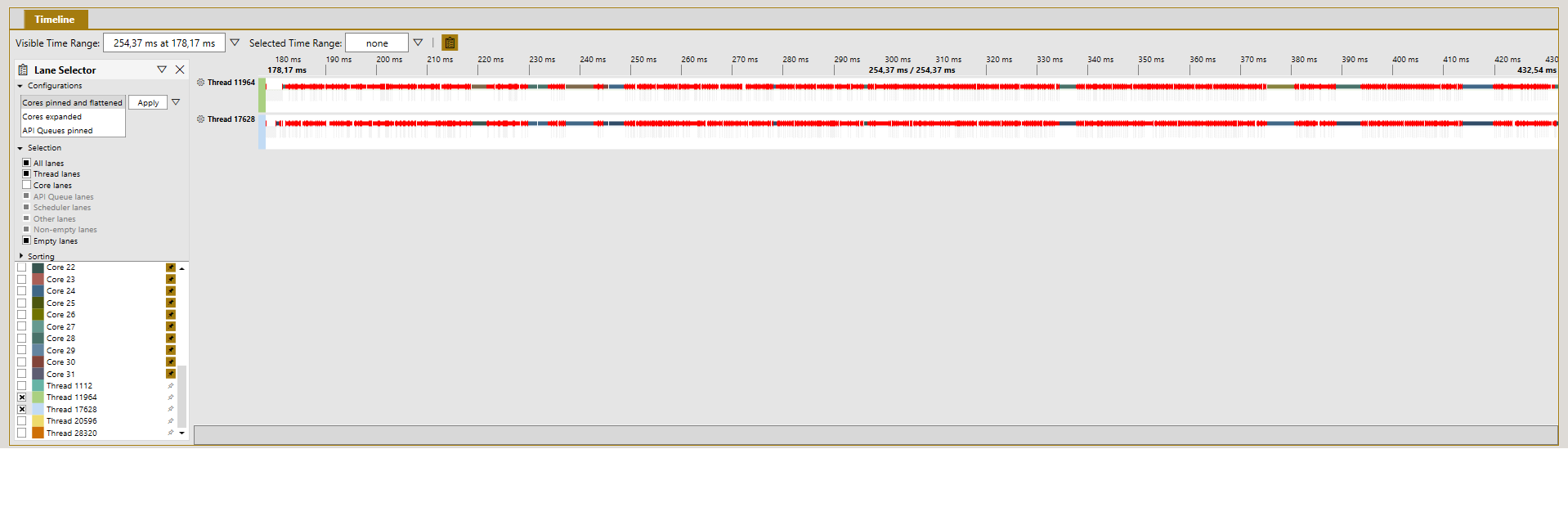
然后,我将此文件导出为. wpix文件。由于wpix使用SQLite作为存储,我使用SQLite浏览器打开导出的文件并查询ReadyThread表,其中包含基于“准备线程”的每个上下文切换的一行数据。
然后我跑:
SELECT COUNT(*) FROM ReadyThread
这意味着运行这段代码的Windows大致包含2.70万上下文切换,与甘地在Linux下的回答观察到的20万相比,这很可能是你看到的时序差异的罪魁祸首。
我在AMDRyzen 9 5950X 16核@3.40 GHz下运行了Windows 10专业版20H2 19042.867。
