
我有一个json文件,看起来像这样:
{"customer": 10, "date": "2017.04.06 12:09:32", "itemList": [{"item": "20126907_EA", "price": 1.88, "quantity": 1.0}, {"item": "20185742_EA", "price": 0.99, "quantity": 1.0}, {"item": "20138681_EA", "price": 1.79, "quantity": 1.0}, {"item": "20049778001_EA", "price": 2.47, "quantity": 1.0}, {"item": "20419715007_EA", "price": 3.33, "quantity": 1.0}, {"item": "20321434_EA", "price": 2.47, "quantity": 1.0}, {"item": "20068076_KG", "price": 28.24, "quantity": 10.086}, {"item": "20022893002_EA", "price": 1.77, "quantity": 1.0}, {"item": "20299328003_EA", "price": 1.25, "quantity": 1.0}], "store": "825f9cd5f0390bc77c1fed3c94885c87"}
我使用以下代码阅读它:
transaction_df = spark \
.read \
.option("multiline", "true") \
.json("../transactions.txt")
输出我有:
+--------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+
|customer|date |itemList |store |
+--------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+
|10 |2017.04.06 12:09:32|[{20126907_EA, 1.88, 1.0}, {20185742_EA, 0.99, 1.0}, {20138681_EA, 1.79, 1.0}, {20049778001_EA, 2.47, 1.0}, {20419715007_EA, 3.33, 1.0}, {20321434_EA, 2.47, 1.0}, {20068076_KG, 28.24, 10.086}, {20022893002_EA, 1.77, 1.0}, {20299328003_EA, 1.25, 1.0}]|825f9cd5f0390bc77c1fed3c94885c87|
+--------+-------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+
我正在寻找的输出:
+--------+--------------+
|customer| itemList|
+--------+--------------+
| 10| 20126907_EA|
| 10| 20185742_EA|
| 10| 20138681_EA|
| 10|20049778001_EA|
| 10|20419715007_EA|
| 10| 20321434_EA|
| 10| 20068076_KG|
| 10|20022893002_EA|
| 10|20299328003_EA|
+--------+--------------+
基本上我在寻找客户和物品数量(10代表客户ID及其各自购买的物品)
您可以分解数组并为每一行选择一个项目。
示例:
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
spark = SparkSession.builder.getOrCreate()
df = spark.read.json("test.json", multiLine=True)
df = df.withColumn("tmp", F.explode_outer("itemList"))
df = df.select(["customer", "tmp.item"])
df.show(10, False)
df.printSchema()
输出:
+--------+--------------+
|customer|item |
+--------+--------------+
|10 |20126907_EA |
|10 |20185742_EA |
|10 |20138681_EA |
|10 |20049778001_EA|
|10 |20419715007_EA|
|10 |20321434_EA |
|10 |20068076_KG |
|10 |20022893002_EA|
|10 |20299328003_EA|
+--------+--------------+
root
|-- customer: long (nullable = true)
|-- item: string (nullable = true)
我将使用SparkSQL而不是dataframes来解决这个问题。两种解决方案都有效。然而,这有一个重要的增强。
#
# 1 - create data file
#
# raw data
json_str = """
{"customer": 10, "date": "2017.04.06 12:09:32", "itemList": [{"item": "20126907_EA", "price": 1.88, "quantity": 1.0}, {"item": "20185742_EA", "price": 0.99, "quantity": 1.0}, {"item": "20138681_EA", "price": 1.79, "quantity": 1.0}, {"item": "20049778001_EA", "price": 2.47, "quantity": 1.0}, {"item": "20419715007_EA", "price": 3.33, "quantity": 1.0}, {"item": "20321434_EA", "price": 2.47, "quantity": 1.0}, {"item": "20068076_KG", "price": 28.24, "quantity": 10.086}, {"item": "20022893002_EA", "price": 1.77, "quantity": 1.0}, {"item": "20299328003_EA", "price": 1.25, "quantity": 1.0}], "store": "825f9cd5f0390bc77c1fed3c94885c87"}
"""
# raw file
dbutils.fs.put("/temp/transactions.json", json_str, True)
上面的代码写了一个临时文件。
#
# 2 - read data file w/schema
#
# use library
from pyspark.sql.types import *
# define schema
schema = StructType([
StructField("customer", StringType(), True),
StructField("date", StringType(), True),
StructField("itemList",
ArrayType(
StructType([
StructField("item", StringType(), True),
StructField("price", DoubleType(), True),
StructField("quantity", DoubleType(), True)
])
), True),
StructField("store", StringType(), True)
])
# read in the data
df1 = spark \
.read \
.schema(schema) \
.option("multiline", "true") \
.json("/temp/transactions.json")
# make temp hive view
df1.createOrReplaceTempView("transaction_data")
这是解决方案中最重要的部分,始终使用带有文本文件的模式。您不希望处理代码猜测格式。如果文件很大,这将需要相当长的时间。

我们可以使用“%sql”魔术命令来执行SparkSQL语句。使用点表示法引用结构数组中的元素。
如果您想在每一行都有此数据,请使用爆炸命令。
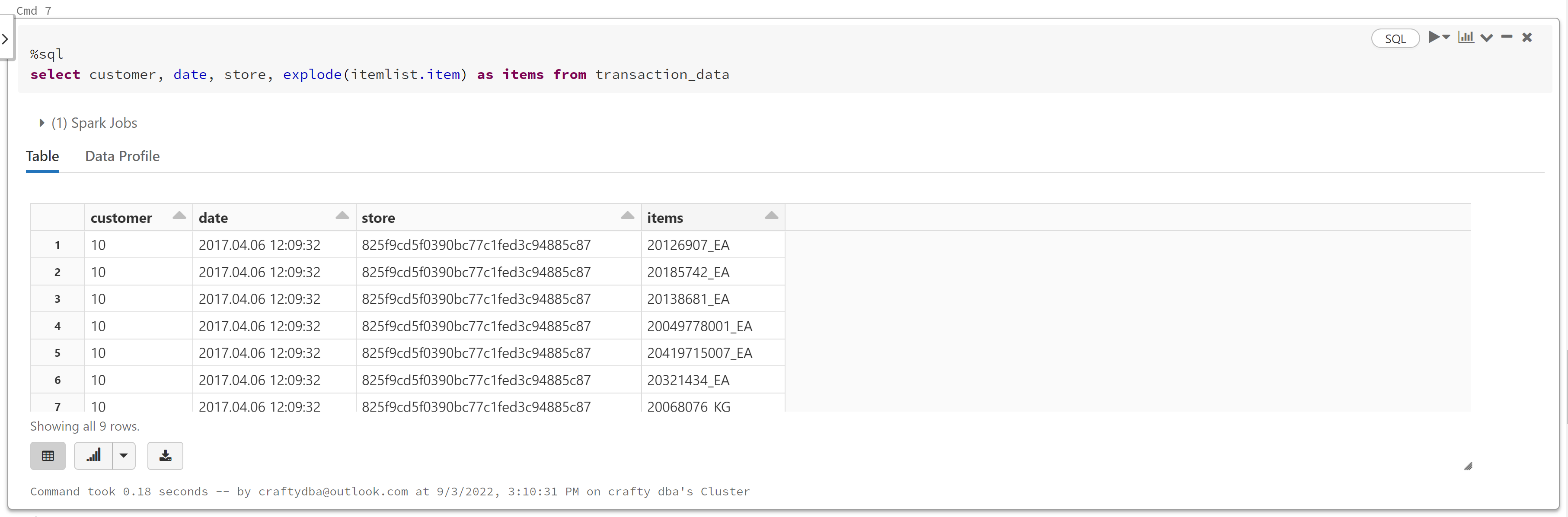
现在我们有了最终的格式,我们可以将数据写入磁盘(可选)。

