
我编写了一个异步数据迁移工具,用于将数据迁移到 AWS DynamoDB。我们在 Dynamo 的目标表中预置了大量资源。
下面是我们的写入容量图和受限制的请求图。如果我们甚至没有接近写入容量,为什么如此大量的请求会受到限制?所有数据最终都在流动,但非常缓慢,因为我会不断重试。
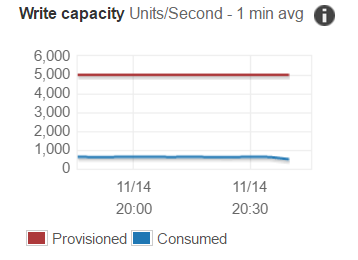
预置的写入吞吐量分布在表的所有分片之间。根据表的大小和吞吐量,数据分布在分片中。
( readCapacityUnits / 3,000 ) + ( writeCapacityUnits / 1,000 ) = initialPartitions (rounded up)
每10 GB的数据也会创建一个分区。
请参见了解分区行为。
如果您的写入请求没有分布在多个分区键之间,那么在达到配置的吞吐量之前,您将遇到被限制的请求。
在您的特定情况下,您的表至少包含5个部分。这意味着每个碎片每秒最多可以使用1000个单位的写入容量。
第二件要考虑的是物品的大小。每个写请求每1KB项目大小消耗1个写容量单位。
请参阅写入容量单位。
总而言之:只有当您的写入或读取请求并行命中所有分片时,您才能使用100%的预配吞吐量。为此,您需要将工作负载分布在多个不同的分区键之间。
