MySQL 删除重复记录

一、MySQL 删除重复记录 介绍
MySQL 是一种数据库应用程序,它以行和列的形式将数据存储在表中。此数据库应用程序可以在表中存储重复记录,这会影响数据库在 MySQL 中的性能。但是,由于各种原因会发生数据重复,在MySQL中使用数据库时,删除表中的重复值是一项重要任务。
通常,最好始终在表上使用唯一约束来存储防止重复行的数据。在本文中,我们将学习如何从 MySQL 数据库中删除重复记录。
让我们借助一个例子来理解它。假设我们有一个名为“student_contacts”的表,其中包含许多重复记录:
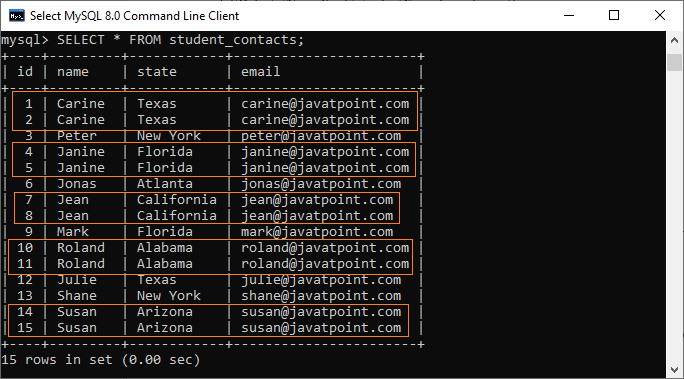
现在,我们将看到如何从表中删除重复记录。MySQL主要通过三种方式去除重复记录。
二、使用删除连接删除重复记录
我们可以在 MySQL 中使用 DELETE JOIN 语句,它允许我们快速删除重复记录。以下语句从表中删除重复行并保留最大 id:
DELETE S1 FROM student_contacts AS S1
INNER JOIN student_contacts AS S2
WHERE S1.id < S2.id AND S1.email = S2.email;
此查询引用 student_contacts 表两次。因此,我们将使用表别名S1和S2。执行语句后,我们将得到以下输出:

上面的输出表明已经从表中删除了5 条记录。我们可以通过执行以下返回表的重复记录的查询来验证这一点。
SELECT name, email, COUNT(name)
FROM student_contacts
GROUP BY name
HAVING COUNT(name) > 1;
它将返回显示空集的输出,如下所示。这意味着重复记录已成功从表中删除。

我们也可以使用SELECT 语句来验证它,在下图中,我们可以看到表中没有可用的重复记录。
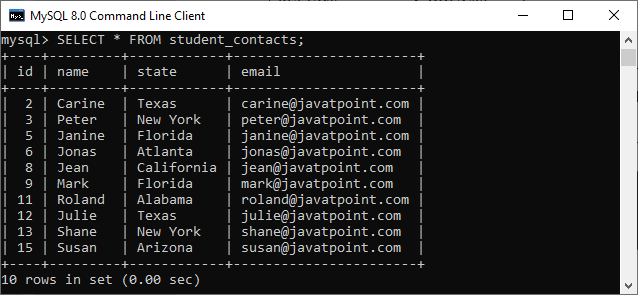
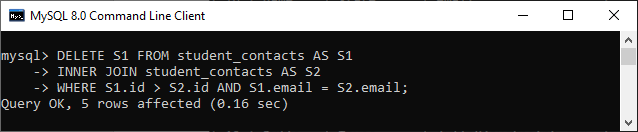
假设我们要删除重复记录并保留表中的最低 id。在这种情况下,我们将使用如下语句:
DELETE S1 FROM student_contacts AS S1
INNER JOIN student_contacts AS S2
WHERE S1.id > S2.id AND S1.email = S2.email;
需要注意的是,在执行查询之前,我们需要再次创建一个包含重复记录的表。执行语句后,我们将得到以下输出:
我们也可以使用 SELECT 语句来验证它。在下图中,我们可以看到具有较高 id 的重复记录已被删除。
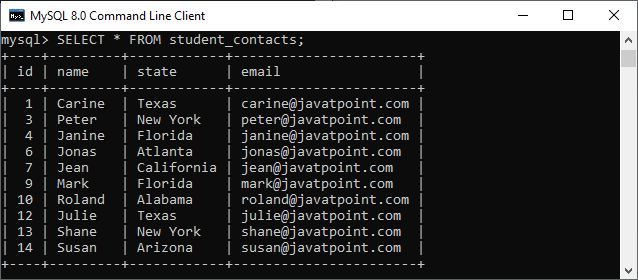
三、使用 ROW_NUMBER() 函数删除重复记录
T ROW_NUMBER() 函数返回其分区内每一行的序号,从 1 开始到分区中存在的行数。
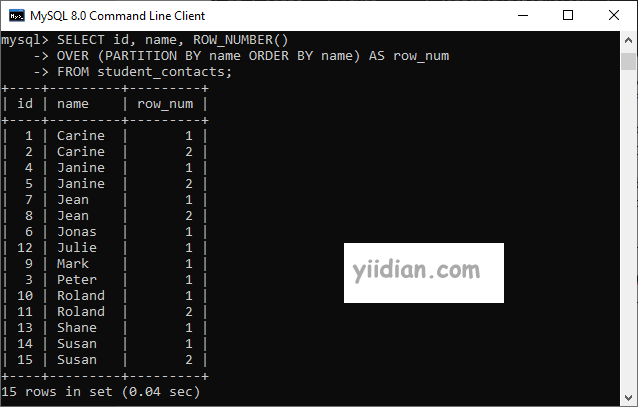
我们可以使用下面的语句,使用ROW_NUMBER() 函数为每一行分配一个序号,如果此查询发现表的name列重复,它将分配大于 1 的行号。
SELECT id, name, ROW_NUMBER()
OVER (PARTITION BY name ORDER BY name) AS row_num
FROM student_contacts;
执行后,我们会得到如下输出:
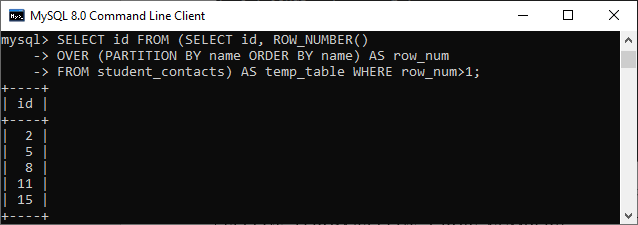
如果您只想获取重复的 id 行,请使用以下语句:
SELECT id FROM (SELECT id, ROW_NUMBER()
OVER (PARTITION BY name ORDER BY name) AS row_num
FROM student_contacts) AS temp_table WHERE row_num>1;
此语句重新运行以下输出:
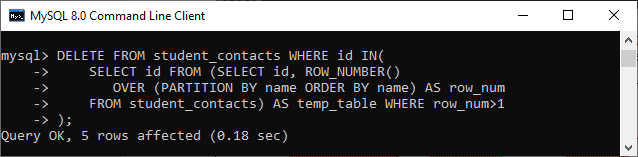
我们现在可以借助DELETE语句从student_contacts表中删除重复记录和一个子查询在WHERE子句中,请参阅以下声明:
DELETE FROM student_contacts WHERE id IN(
SELECT id FROM (SELECT id, ROW_NUMBER()
OVER (PARTITION BY name ORDER BY name) AS row_num
FROM student_contacts) AS temp_table WHERE row_num>1
);
执行后,我们将得到如下图的输出,我们可以看到该语句已从表中删除了 5 条记录。您可以使用 SELECT 语句验证是否删除了重复行。
四、使用中间表删除重复行
我们还可以使用中间表从表中删除重复记录。以下是借助中间表删除重复记录的要点:
1. 创建一个与我们将用来删除重复记录的原始表具有相同结构的新表。
mysql> CREATE TABLE new_table_name LIKE source_table_name;
2. 将原始表的唯一(不同)行插入到新创建的表中。
mysql> INSERT INTO new_table_name
SELECT * FROM source_table_name
GROUP BY column; //It is the name of a column that contains duplicate values.
3. 删除原表,将新建的表重命名为原表。
mysql> DROP TABLE source_table_name;
mysql> ALTER TABLE new_table_name RENAME TO source_table_name;
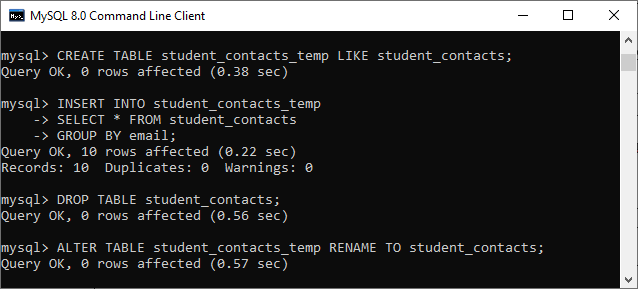
让我们借助以下使用中间表删除重复记录的查询来了解上述步骤:
第1步:
mysql> CREATE TABLE student_contacts_temp LIKE student_contacts;
第2步:
mysql> INSERT INTO student_contacts_temp
SELECT * FROM student_contacts
GROUP BY email; //It is the name of column that contains duplicate values.
第 3 步:
mysql> DROP TABLE student_contacts;
mysql> ALTER TABLE student_contacts_temp RENAME TO student_contacts;
请参阅下图以了解上述步骤。
热门文章
优秀文章
