Java HashMap原理分析

本文主要介绍HashMap工作原理,了解哈希算法的计算过程。
1 什么是哈希(散列)(Hashing)
哈希是通过使用方法hashCode() 将对象转换为整数形式的过程。必须正确编写hashCode() 方法,以提高HashMap的性能。在这里,我使用自己的类的键,以便可以覆盖hashCode() 方法以显示不同的场景。看下面的代码:
package com.yiidian;
/**
* 一点教程网: http://www.yiidian.com
*/
/**
* Java HashMap的工作原理分析
*/
//Key类覆盖了hashCode方法和equals方法
class Key
{
String key;
Key(String key)
{
this.key = key;
}
@Override
public int hashCode()
{
return (int)key.charAt(0);
}
@Override
public boolean equals(Object obj)
{
return key.equals((String)obj);
}
}
上面的Key类覆盖的hashCode() 方法返回第一个字符的ASCII值作为哈希码。因此,只要key的第一个字符相同,哈希码就会相同(当然以上程序只是演示,实际开发中不应该这样覆盖hashCode()方法)。由于HashMap还允许使用null键,因此null的哈希码将始终为0。
2 HashMap hashCode()方法
2.1 什么是hashcode
hashcode就是通过hash函数得来的,通俗的说,就是通过某一种算法得到的,hashcode就是在hash表中有对应的位置。
每个对象都有hashcode,对象的hashcode怎么得来的呢?
首先一个对象肯定有物理地址,网上有人把对象的hashcode说成是对象的地址,事实上这种看法是不全面的,确实有些JVM在实现时是直接返回对象的存储地址,但是大多时候并不是这样,只能说可能存储地址有一定关联,
那么对象如何得到hashcode呢?通过对象的内部地址(也就是物理地址)转换成一个整数,然后该整数通过hash函数的算法就得到了hashcode,所以,hashcode是什么呢?就是在hash表中对应的位置。这里如果还不是很清楚的话,举个例子,hash表中有 hashcode为1、hashcode为2、(...)3、4、5、6、7、8这样八个位置,有一个对象A,A的物理地址转换为一个整数17(这是假如),就通过直接取余算法,17%8=1,那么A的hashcode就为1,且A就在hash表中1的位置。
2.2 为什么要使用hashcode
HashCode的存在主要是为了查找的快捷性, HashCode是用来在散列存储结构中确定对象的存储地址的 ( 用hashcode来代表对象在hash表中的位置 ) , hashCode 存在的重要的原因之一就是在 HashMap(HashSet 其实就是HashMap) 中使用(其实Object 类的 hashCode 方法注释已经说明了 ),HashMap 之所以速度快,因为他使用的是散列表,根据 key 的 hashcode 值生成数组下标(通过内存地址直接查找,不需要判断, 但是需要多出很多内存,相当于以空间换时间)
比如:我们有一个能存放1000个数这样大的内存中,在其中要存放1000个不一样的数字,用最笨的方法,就是存一个数字,就遍历一遍,看有没有相同得数,当存了900个数字,开始存901个数字的时候,就需要跟900个数字进行对比,这样就很麻烦,很是消耗时间,用hashcode来记录对象的位置,来看一下。hash表中有1、2、3、4、5、6、7、8个位置,存第一个数,hashcode为1,该数就放在hash表中1的位置,存到100个数字,hash表中8个位置会有很多数字了,1中可能有20个数字,存101个数字时,他先查hashcode值对应的位置,假设为1,那么就有20个数字和他的hashcode相同,他只需要跟这20个数字相比较(equals),如果每一个相同,那么就放在1这个位置,这样比较的次数就少了很多,实际上hash表中有很多位置,这里只是举例只有8个,所以比较的次数会让你觉得也挺多的,实际上,如果hash表很大,那么比较的次数就很少很少了。通过对原始方法和使用hashcode方法进行对比,我们就知道了hashcode的作用,并且为什么要使用hashcode了。
3 HashMap equals()方法
equals方法用于判断2个对象是否相等。此方法由Object类提供。您可以在您的类中重写此方法以提供您自己的实现。
HashMap使用equals() 比较key是否相等。如果equals() 方法返回true,则它们相等,否则不相等。
4 HashMap 存储桶
存储桶是HashMap数组的一个元素。它用于存储节点。两个或多个节点可以具有相同的存储桶。在那种情况下,链接列表结构用于连接节点,存储桶与容量之间的关系如下:
存储桶容量 = 存储桶节点数量 * 负载因子
一个存储桶可以有多个节点,这取决于hashCode() 方法。您的hashCode() 方法越好,您的存储桶将被利用得越好。
5 HashMap的索引计算过程
键的哈希码可能足够大以创建数组。生成的哈希码可能在整数范围内,如果我们为该范围创建数组,则很容易导致outOfMemoryException。因此我们生成索引以最小化数组的大小。基本上执行以下操作来计算索引。
index= hashCode(key)&(n-1)。
其中n是存储桶数或数组大小。在我们的示例中,我将n设置为默认大小16。
HashMap map = new HashMap();

插入键值对:在HashMap上方放置一个键值对
map.put(new Key("vishal"), 20);
步骤:
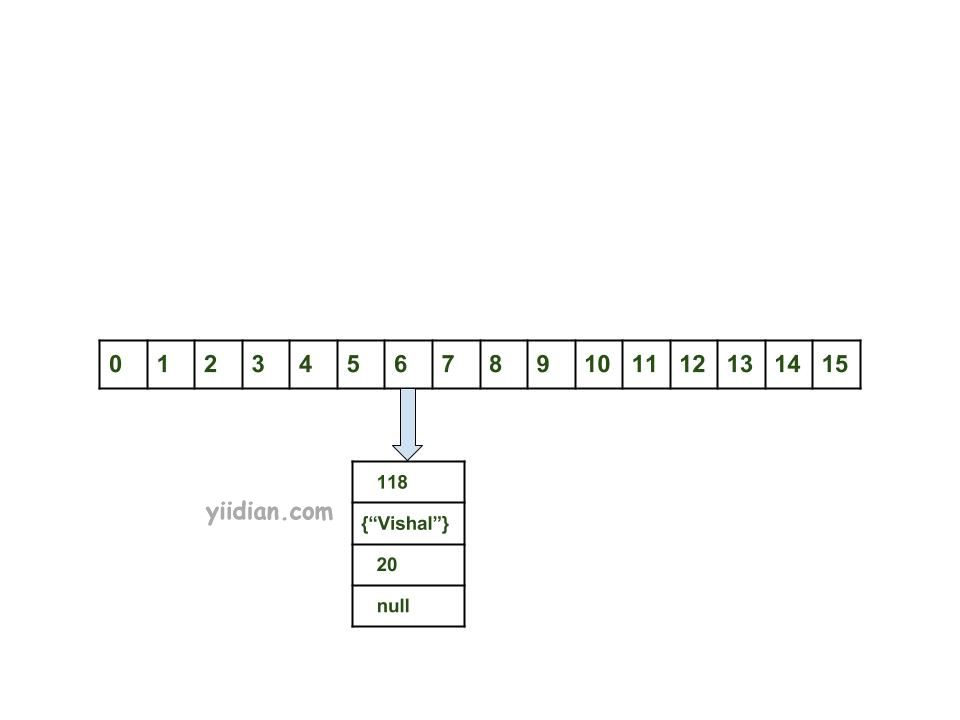
- 计算key{"vishal"}的哈希码。它将生成为118。
- 使用索引方法计算索引将为6。
- 创建一个节点对象为:
{
int hash = 118
// {"vishal"} is not a string but
// an object of class Key
Key key = {"vishal"}
Integer value = 20
Node next = null
}
4.如果没有其他对象,则将该对象放置在索引6处。
现在,HashMap变为:
插入另一个键值对:
map.put(new Key("sachin"), 30);
步骤:
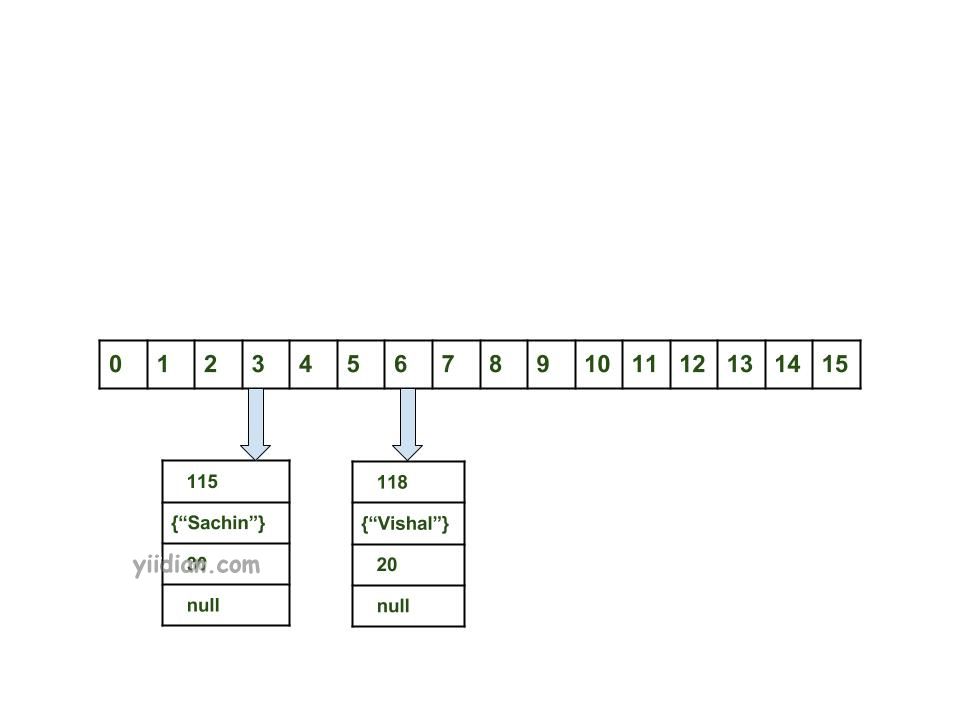
- 计算密钥{"sachin"}的hashCode。它将生成为115。
- 使用索引方法计算索引将为3。
- 创建一个节点对象为:
{
int hash = 115
Key key = {"sachin"}
Integer value = 30
Node next = null
}
如果此处没有其他对象,则将该对象放置在索引3处。
现在,HashMap变为:
万一发生碰撞:现在,再放一对:
map.put(new Key("vaibhav"), 40);
步骤:
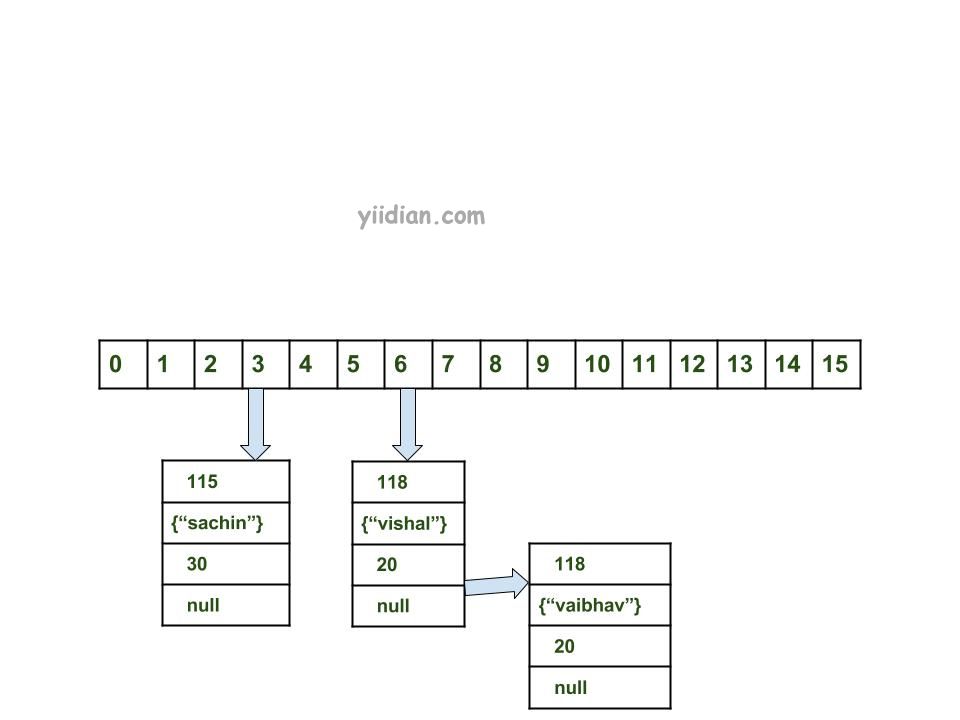
- 计算密钥{"vaibhav"}的哈希码。它将生成为118。
- 使用索引方法计算索引将为6。
- 创建一个节点对象为:
{
int hash = 118
Key key = {"vaibhav"}
Integer value = 40
Node next = null
}
4. 如果此处没有其他对象,则将该对象放置在索引6处。
5. 在这种情况下,将在索引6处找到一个节点对象–这是一种冲突情况。
6. 在这种情况下,请通过hashCode() 和equals() 方法检查两个键是否相同。
7. 如果键相同,则用当前值替换该值。
8. 否则,通过链接列表将此节点对象连接到先前的节点对象,并且两者都存储在索引6中。
现在,HashMap变为:
6 HashMap get()方法
现在让我们尝试一些获取值的方法。get(K key) 方法用于通过其键获取值。如果您不知道key,则无法获取值。
6.1 获取key为sachin的数据
map.get(new Key("sachin"));
步骤:
- 计算密钥{"sachin"}的哈希码。它将生成为115。
- 使用索引方法计算索引将为3。
- 转到数组的索引3并将第一个元素的键与给定的键进行比较。如果两者相等,则返回该值,否则检查下一个元素是否存在。
- 在我们的例子中,它是第一个元素,返回值为30。
6.2 获取key为vaibahv的数据
步骤:
- 计算key{"vaibhav"}的哈希码。它将生成为118。
- 使用索引方法计算索引将为6。
- 转到数组的索引6,然后将第一个元素的键与给定的键进行比较。如果两者相等,则返回该值,否则检查下一个元素是否存在。
- 在我们的情况下,找不到它作为第一个元素,而节点对象的下一个也不为空。
- 如果节点的下一个为null,则返回null。
- 如果节点的next不为空,则遍历第二个元素并重复过程3,直到找不到键或next不为空。
7 HashMap原理分析完整代码
package com.yiidian;
/**
* 一点教程网: http://www.yiidian.com
*/
/**
* Java HashMap的工作原理分析
*/
import java.util.HashMap;
class Key {
String key;
Key(String key)
{
this.key = key;
}
@Override
public int hashCode()
{
int hash = (int)key.charAt(0);
System.out.println("hashCode for key: "
+ key + " = " + hash);
return hash;
}
@Override
public boolean equals(Object obj)
{
return key.equals(((Key)obj).key);
}
}
//
public class Demo {
public static void main(String[] args)
{
HashMap map = new HashMap();
map.put(new Key("vishal"), 20);
map.put(new Key("sachin"), 30);
map.put(new Key("vaibhav"), 40);
System.out.println();
System.out.println("Value for key sachin: " + map.get(new Key("sachin")));
System.out.println("Value for key vaibhav: " + map.get(new Key("vaibhav")));
}
}
输出结果为:
hashCode for key: vishal = 118
hashCode for key: sachin = 115
hashCode for key: vaibhav = 118
hashCode for key: sachin = 115
Value for key sachin: 30
hashCode for key: vaibhav = 118
Value for key vaibhav: 40
热门文章
优秀文章
