
我正在使用PDFClown Java库创建PDF文件。
有时,当使用Adobe Acrobat Reader打开这些文件时,我会收到著名的错误消息:
“此页面存在错误。Acrobat可能无法正确显示该页面。请与创建PDF文档的人员联系以更正此问题。”
当读取(使用Adobe)附加文件时,只有向下滚动到第8页,然后向上滚动到3'td页时才显示错误。或者,缩小到33.3%也会产生消息。
只是为了记录,Foxit reader读取文件是完美无缺的,以及其他类似浏览器的PDF阅读器。
我的问题是:
>
我的文件有什么问题??(档案附后)
我怎么才能发现它有什么问题?是否有一种工具可以告诉您错误所在?
谢谢!
好吧,这不容易-
由于PDFClown中的一个错误,我在PDF页面中的主要信息流已被破坏。在它结束后,它有一个它的过去实例的副本。这导致部分文本部分没有启动命令“bt”--这在流的末尾留下了一个没有“bt”的“et”。
一旦我纠正了这一点,它运行得很好。
谢谢大家的帮助。如果没有@Bruno建议的工具RUPS,我将会有更多的困难来调试它。
编辑:
bug在buffer.java:clone()(第217行)中
而不是行:
clone.append(数据);
需要:
clone.append(data,0,this.length);
如果不进行此更正,它将克隆整个数据缓冲区,并将克隆缓冲区的长度设置为data[].length。如果buffer.length小于data[].length,这就很有问题了。在我的例子中,结果是在小溪的末端有垃圾。
当读取(使用Adobe)附加文件时,只有向下滚动到第8页,然后向上滚动到3'td页时才显示错误。或者,缩小到33.3%也会产生消息。
好吧,我变得更容易,我只需要打开PDF并使用光标键向下滚动。第3页的顶部2厘米一出现,消息就出现了。
我的档案怎么了??
第1页和第2页的内容看起来还可以,那么我们来看看第3页的内容。
我最初将问题归因于在文本对象外部使用特定于文本的操作(特别是Tf和Tw)是错误的,正如Stefano Chizzolini所指出的:在文本对象外部确实允许一些与文本相关的操作,即文本状态操作,cf。图9来自PDF规范:
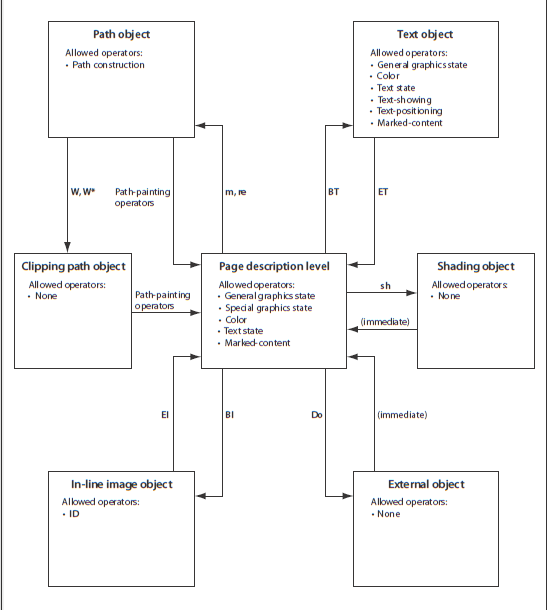
因此,虽然不太常见,但页面描述级别的文本状态操作是完全可以的。
在我错误地试图解释这个问题之后,OP自己的回答表明
PDF页面中的主要信息流已损坏。在它结束后,它有一个它的过去实例的副本。这导致部分文本部分没有启动命令“bt”--这在流的末尾留下了一个没有“bt”的“et”。
一个没有事先BT的ET确实是一个错误,而且很可能伴随着错误级别的操作。但是,在检查第三个页面(本期的重点页面)的流内容时,我找不到任何不匹配的ET。但是,在检查过程中,我发现内容流包含2000多个尾随的0字节!Adobe Reader似乎无法处理这0个字节。
OP发现的bug可以解释问题:
在buffer.java中:clone()(第217行)
而不是行:
clone.append(data);
需要:
clone.append(data, 0, this.length);
如果不进行此更正,它将克隆整个数据缓冲区,并将克隆的缓冲区的长度设置为数据[].length。如果buffer.length``小于data[].lengts,这就很有问题了。
尾随0字节可能是这种缓冲区复制错误的影响。
此外,由OP发现的症状(在它结束后,它有一个它的过去实例的副本)也可能是这样一个bug的影响。所以我假设OP在不同的页面上发现了这些症状,而不是第3页,但是修复bug可以治愈所有症状。
我怎么才能发现它有什么问题?有没有一个工具可以告诉你错误在哪里?
有PDF语法检查器,例如Adobe Acrobat中包含的预飞行工具。但即使在你的档案上也失败了。
因此,基本上您必须提取页面内容(使用PDF浏览器,例如RUPS),并手动检查另一个屏幕上的PDF规范。
