
我对MapReduce框架非常困惑。我从不同的来源阅读到这一点感到困惑。顺便说一句,这是我对MapReduce工作的想法
1. Map()-->emit <key,value>
2. Partitioner (OPTIONAL) --> divide
intermediate output from mapper and assign them to different
reducers
3. Shuffle phase used to make: <key,listofvalues>
4. Combiner, component used like a minireducer wich perform some
operations on datas and then pass those data to the reducer.
Combiner is on local not HDFS, saving space and time.
5. Reducer, get the data from the combiner, perform further
operation(probably the same as the combiner) then release the
output.
6. We will have n outputs parts, where n is the number
of reducers
这基本上是正确的?我的意思是,我发现了一些来源,说明合成器是洗牌阶段,它基本上是按键分组每条记录…
合成器与洗牌阶段一点也不相似。你所描述的洗牌是错误的,这是你困惑的根源。
混排只是将key从map复制到duce,与key生成无关。这是Reducer的第一阶段,其他两个正在排序然后减少。
组合就像在本地执行一个还原器,对于每个映射器的输出。它基本上就像一个还原器(它也扩展了Reducer类),这意味着,像一个还原器一样,它将映射器为同一个键发出的本地值分组。
分区实际上是将映射输出键分配给特定的减少任务,但它不是可选的。用您自己的实现覆盖默认的HashParkator是可选的。
我试图将这个答案保持在最低限度,但您可以在Tom White的《Hadoop:权威指南》一书中找到更多信息,正如Azim所建议的那样,以及这篇文章中的一些相关内容。
将组合器视为一个小型还原器阶段,它仅对每个节点内的map任务的输出起作用,然后再将其发送到实际的还原器。
以经典的WordCount为例,map任务处理的每个单词的map阶段输出为(word,1)。让我们假设要处理的输入是
"她住在印度一个大城市郊区有个大车库的大房子里"
如果没有组合器,map阶段会发出(大,1)三次,(a,1)三次,(in,1)两次。但是当使用组合器时,map阶段会发出(大,3),(a,3)和(in,2)。请注意,这些单词中的每一个的出现都是在map阶段内本地聚合的,然后才会发出输出以减少相位。在使用组合器的用例中,它将进行优化,以确保由于本地聚合,从map到duce的流量最小化。
在混洗阶段,来自不同映射阶段的输出被重定向到正确的还原阶段。这由框架内部处理。如果使用分区器,则对输入进行混洗以相应地减少会很有帮助。
我不认为合并器是Shuffle和Sort阶段的一部分。合并器本身是作业生命周期的阶段之一(可选)。
这些阶段的流水线可以是这样的:Map-
在这些阶段中,Map、分区和组合器在同一个节点上运行。Hadoop根据资源的可用性和可访问性以最佳方式动态选择节点运行Reduce阶段。Shuffle and Sort是一个重要的中间层阶段,适用于Map和Reduce节点。
当客户端提交作业时,映射阶段开始处理以块形式跨节点存储的输入文件。映射器逐个处理文件的每一行,并将生成的结果放入100MB的内存缓冲区(每个映射器的本地内存)。当这个缓冲区被填充到某个阈值时,默认情况下为80%,这个缓冲区被排序,然后存储到磁盘中(作为文件)。每个Mapper可以生成多个这样的中间排序拆分或文件。当Mapper完成块的所有行时,所有这样的拆分被合并在一起(形成一个文件),排序(基于键),然后组合器阶段开始处理这个文件。请注意,如果没有Paritition阶段,只会生成一个中间文件,但在Paritition的情况下,会根据开发人员的逻辑生成多个文件。下图来自Oreilly Hadoop:权威指南,可以帮助您更详细地理解这个概念。
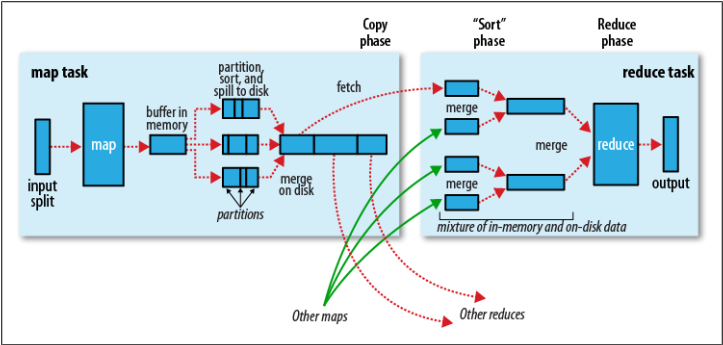
稍后,Hadoop根据键值将合并后的文件从每个Mapper节点复制到Reducer节点。也就是说,同一键的所有记录都将被复制到同一个Reducer节点。
我认为,您可能深入了解SS和减少阶段的工作,因此不会详细介绍这些主题。
此外,如需更多信息,我建议您阅读Oreilly Hadoop:权威指南。它的Hadoop很棒的书。
