
我有以下建议,
contact <- tribble(
~name, ~phone, ~email,
'John', 123, 'john_abc@gmail.com',
'John', 456, 'john_abc@gmail.com',
'John', 456, 'john_xyz@gmail.com',
'John', 789, 'john_pqr@gmail.com'
)
如果电话或电子邮件相同,我想合并电话号码和电子邮件,所需的输出如下,
contact_combined <- tribble(
~name, ~phone, ~email,
'John', '123;456', 'john_abc@gmail.com;john_xyz@gmail.com',
'John', '789', 'john_pqr@gmail.com'
)
我尝试过先按姓名和电话分组,然后按姓名和电子邮件分组,但它没有给我预期的结果。我一直在寻找解决这个问题的算法方法,有人能给我一个建议吗?
注意:这里的问题不是列中值的折叠。这是关于选择折叠的记录。
图表可以帮助解决这个问题。
library(igraph)
# creates a matrix which tells whether pairs of vector elements are equal or not
equal_mat <- function(x) {
outer(x, x, '==')
}
m.adj <- equal_mat(contact$phone) | equal_mat(contact$email)
g <- graph_from_adjacency_matrix(m.adj, mode='undir')
t(sapply(split(contact, components(g)$membership), function(group)
sapply(group, function(column)
paste(sort(unique(column)), collapse=';')))) %>%
as_tibble()
# # A tibble: 2 × 3
# name phone email
# <chr> <chr> <chr>
# 1 John 123;456 john_abc@gmail.com;john_xyz@gmail.com
# 2 John 789 john_pqr@gmail.com
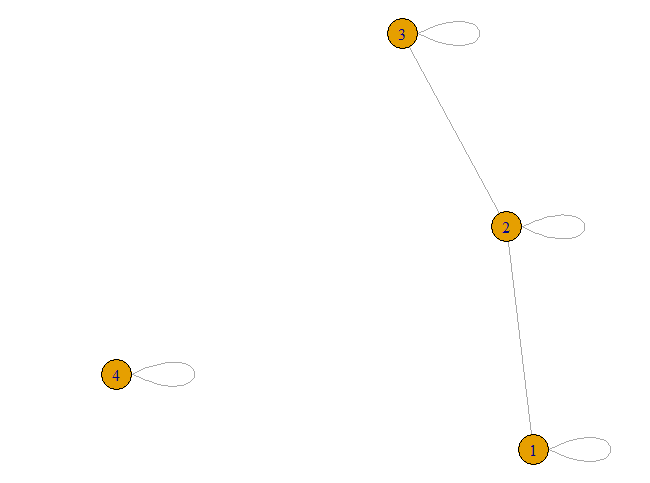
触点1-3形成一个连接的组件,而没有连接的触点4是另一个组件。每个这样的组件应该在最终输出中合并成一个触点。
我们从相邻矩阵m. adj创建图,它告诉哪些顶点(节点)连接,并使用
components(g)$membership
[1] 1 1 1 2
这准确地告诉我们上面看到的:触点1-3形成组件1,触点编号4是组件2。现在我们可以折叠每个组件中的值。
我想igraph将是一个很好的开始(通过它您可以使用分解来集群连接的子组)
contact %>%
select(c(2, 3, 1)) %>%
graph_from_data_frame() %>%
decompose() %>%
lapply(function(x) {
aggregate(
. ~ name, get.data.frame(x),
function(v) toString(unique(v))
)
}) %>%
bind_rows() %>%
setNames(names(contact))
这给了
name phone email
1 John 123, 456 john_abc@gmail.com, john_xyz@gmail.com
2 John 789 john_pqr@gmail.com
更tidyverse的方式(感谢@akrun的评论)
contact %>%
relocate(name, .after = last_col()) %>%
graph_from_data_frame() %>%
decompose() %>%
map(~ .x %>%
get.data.frame() %>%
reframe(across(everything(), ~ str_c(unique(.x), collapse = ";")), .by = "name")) %>%
list_rbind() %>%
setNames(names(contact))
这是sdata. table方法
setDT(contact)
# set keys
setkey(contact, name, phone, email)
# self join on each unique key, filter and summarise on the fly
ans <- contact[contact, c("phone2", "email2") := {
temp <- contact[ name == i.name &
(phone %in% contact[name == i.name & email == i.email, ]$phone |
email %in% contact[name == i.name & phone == i.phone, ]$email), ]
email_temp <- paste0(unique(temp$email), collapse = ";")
phone_temp <- paste0(unique(temp$phone), collapse = ";")
list(phone_temp, email_temp)
}, by = .EACHI]
# final step
unique(ans, by = c("name", "phone2", "email2"))[, .(name, phone = phone2, email = email2)]
# name phone email
# 1: John 123;456 john_abc@gmail.com;john_xyz@gmail.com
# 2: John 789 john_pqr@gmail.com
解释
# so, for the first row, the variable 'temp' is calculated as follows
contact[ name == 'John' &
(phone %in% contact[name == 'John' & email == 'john_abc@gmail.com', ]$phone |
email %in% contact[name == 'John' & phone == 123, ]$email), ]
# name phone email
# 1: John 123 john_abc@gmail.com
# 2: John 456 john_abc@gmail.com
# 3: John 456 john_xyz@gmail.com
# then, put the unique emails together in a string using
# email_temp <- paste0(unique(temp$email), collapse = ";")
# and do the same for the phones using
# phone_temp <- paste0(unique(temp$phone), collapse = ";")
# and return there two strings to the columns "phone2" ans "email2"
#repeat for each unique key-combination (.EACHI)
