
Spring环境中有一个大现象,或者我大错特错了。但是默认的Spring@Transactional注释不是ACID,而是缺乏隔离的ACD。这意味着如果你有方法:
@Transactional
public TheEntity updateEntity(TheEntity ent){
TheEntity storedEntity = loadEntity(ent.getId());
storedEntity.setData(ent.getData);
return saveEntity(storedEntity);
}
如果两个线程以不同的计划更新进入会发生什么。他们都从数据库加载实体,他们都应用自己的更改,然后第一个被保存并提交,当第二个被保存并提交时,第一个更新丢失了。真的是这样吗?调试器就是这样工作的。
你没有丢失数据。把它想象成改变代码中的变量。
int i = 0;
i = 5;
i = 10;
你“丢了”5吗?不,你换了它。
现在,你提到的多线程的棘手部分是,如果这两个SQL更新同时发生呢?
从纯更新的角度来看(忘记读取),这没有什么不同。数据库将使用锁来序列化更新,因此一个更新仍然先于另一个更新。第二个自然获胜。
但是,这里有一个危险…
如果更新是基于当前状态有条件的怎么办?
public void updateEntity(UUID entityId) {
Entity blah = getCurrentState(entityId);
blah.setNumberOfUpdates(blah.getNumberOfUpdates() + 1);
blah.save();
}
现在你有一个数据丢失的问题,因为如果两个并发线程执行读取(getCurrentState),它们将各自添加1,到达相同的数字,第二次更新将丢失前一次更新的增量。
有两种解决方案。
selects)不持有任何排他锁,因此不会阻塞,无论它们是否在事务中。Serializable实际上将为读取的每一行获取并持有排他锁,并且仅在事务提交或回滚时释放这些锁。UPDATE语句应该使这个原子为我们,即UPDATE实体SETnumber_of_updates=number_of_updates1 WHEREentity_id = ? 。一般来说,后者的可扩展性要高得多。你持有的锁越多,持有的时间越长,你得到的阻塞就越多,因此吞吐量就越少。
为了补充上面的注释,@Transactional和“丢失更新”的这种情况并没有错,但是,它可能看起来令人困惑,因为它不符合我们的期望,即@Transactional可以防止“丢失更新”。
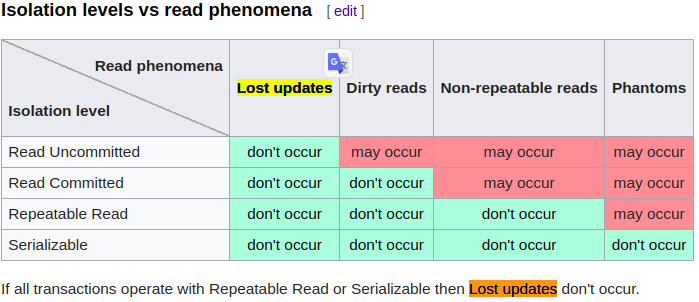
READ_COMMITED隔离级别可能会出现更新丢失问题,这也是大多数DB和JPA提供程序的默认设置。
为了防止这种情况,需要使用@Transactional(隔离=隔离。REPEATABLE_READ)。不需要SERIALIZABLE,那就大材小用了。
著名的JPA冠军Vlad Mihalcea在他的文章中给出了很好的解释:https://vladmihalcea.com/a-beginners-guide-to-database-locking-and-the-lost-update-phenomena/
还值得一提的是,更好的解决方案是使用@Version,它也可以通过乐观锁定方法防止丢失更新。
问题可能来自维基页面https://en.wikipedia.org/wiki/Isolation_(database_systems),其中显示“丢失更新”是一个比“脏读”更弱的问题,并且从来都不是一个案例,但是,下面的文本相互矛盾:
你没有大错特错,你的问题是一个非常有趣的观察。我相信(根据你的评论)你是在你非常具体的情况下思考它,而这个主题要广泛得多。让我们一步一步来。
酸
ACID中的I确实代表隔离。但这并不意味着两个或多个事务需要一个接一个地执行。它们只需要隔离到某种程度。大多数关系数据库允许在事务上设置隔离级别,甚至允许您从其他未提交的事务中读取数据。这种情况是否可以,取决于特定的应用程序。例如,参见mysql留档:
https://dev.mysql.com/doc/refman/5.7/en/innodb-transaction-isolation-levels.html
当然,您可以将隔离级别设置为可序列化并实现您的期望。
现在,我们还有不支持ACID的非关系型数据库。最重要的是,如果你开始使用一个数据库集群,你可能需要接受数据的最终一致性,这甚至可能意味着刚刚写入一些数据的同一个线程在读取时可能不会接收到它。同样,这是一个非常特定于特定应用程序的问题——我能承受一会儿不一致的数据来换取快速写入吗?
您可能会倾向于在银行或某些金融系统中以可序列化的方式处理一致的数据,并且您可能会对社交应用程序中不太一致的数据感到满意,但会获得更高的性能。
更新丢失-是这样吗?
是的,会是这样的。
我们害怕序列化吗?
是的,它可能会变得很糟糕:-)但是了解它是如何工作的以及后果是什么是很重要的。我不知道这种情况是否仍然存在,但是大约10年前我在一个项目中遇到过使用DB2的情况。由于非常具体的场景,DB2在整个表上执行锁升级到排他锁,有效地阻止任何其他连接访问表,即使是读取。这意味着一次只能处理一个连接。
因此,如果您选择使用可序列化级别,您需要确保您的事务实际上是快速的,并且实际上是需要的。也许在您编写时其他线程正在读取数据是可以的?想象一下这样一个场景,您的文章有一个评论系统。突然发表了一篇病毒文章,每个人都开始评论。评论的单个写事务需要100毫秒。100个新评论事务排队,这将有效地阻止在接下来的10秒内读取评论。我确信,在这里使用读提交绝对足够了,并允许您实现两件事:更快地存储评论,并在编写时读取它们。
长话短说:这完全取决于您的数据访问模式,没有灵丹妙药。有时需要可串行化,但它会带来性能损失,有时读取未提交会很好,但会带来不一致的惩罚。
