
我在DynamoDB表上的更新中看到了一些节流。我知道节流以每秒为基础工作,高于预配容量的峰值有时可以被吸收,但不能保证。我知道应该均匀分配负载,但我没有这样做。
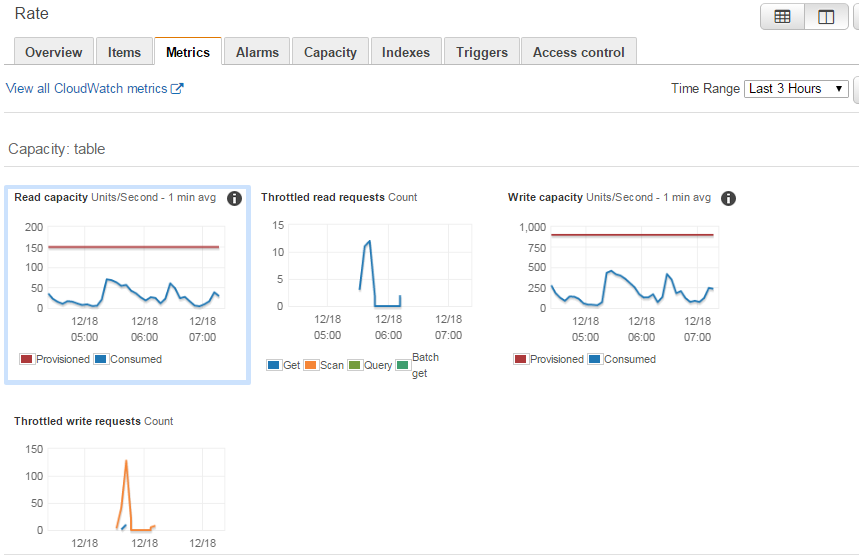
但是请查看指标中的1分钟平均图表;附件。使用的容量远低于预置容量。这些限制来自哪里?因为所有写入都转到了特定的分片?
没有批处理写入。工作负载分布是一种很难控制的事情。
DynamoDB建立在这样一个假设之上,即要充分发挥预配吞吐量的潜力,您的读取和写入必须在空间(哈希/范围键)和时间上均匀分布(并非所有内容都在完全相同的一秒内进入)。
根据图表上分配的吞吐量,您仍然很可能在一个分片上,但是如果您之前将吞吐量提高到当前水平以上并将其降低到现在的水平,则可能有两个或更多分片。虽然这是需要注意的事情,但它可能不是直接导致这种限制行为的原因。如果您的表中有很多数据,超过10 GB,那么您肯定会有多个分片。这意味着您的表中可能有很多冷数据,这可能会导致此问题,但这似乎不太可能。
最可能的问题是您有一些热键。具体来说,您有一条或只有几条记录接收到非常多的读取或写入请求,这导致了节流。本质上,DynamoDB可以支持大量的IOPS进行写入和读取,但您不能将所有这些IOPS应用于少数记录,它们需要在理想情况下均匀分布在所有记录中。
由于您显示的油门数量在10到100之间,因此可能无需担心。只要您使用官方AWS SDK,它就会自动处理重试,并以指数退避方式重试多次请求,然后完全放弃。
虽然在许多情况下很难控制对表的读写分布,但可能值得再看看您的哈希/范围键设计,以确保它确实最适合您对表的读写模式。此外,对于读取,您可以通过Memcached或Redis使用缓存,即使缓存在几分钟或几秒钟内过期,以帮助减少热键的影响。对于写入,您需要查看应用程序中的逻辑,以确保没有执行任何可能导致此问题的不必要的写入。
与批处理写入有关的最后一点:DynamoDB中的批处理操作不会减少不同子请求所消耗的读取或写入量,它只是减少了发出多个HTTP请求的开销。虽然批处理请求通常有助于提高吞吐量,但它们在降低DynamoDB中节流的可能性方面并不有用。
