
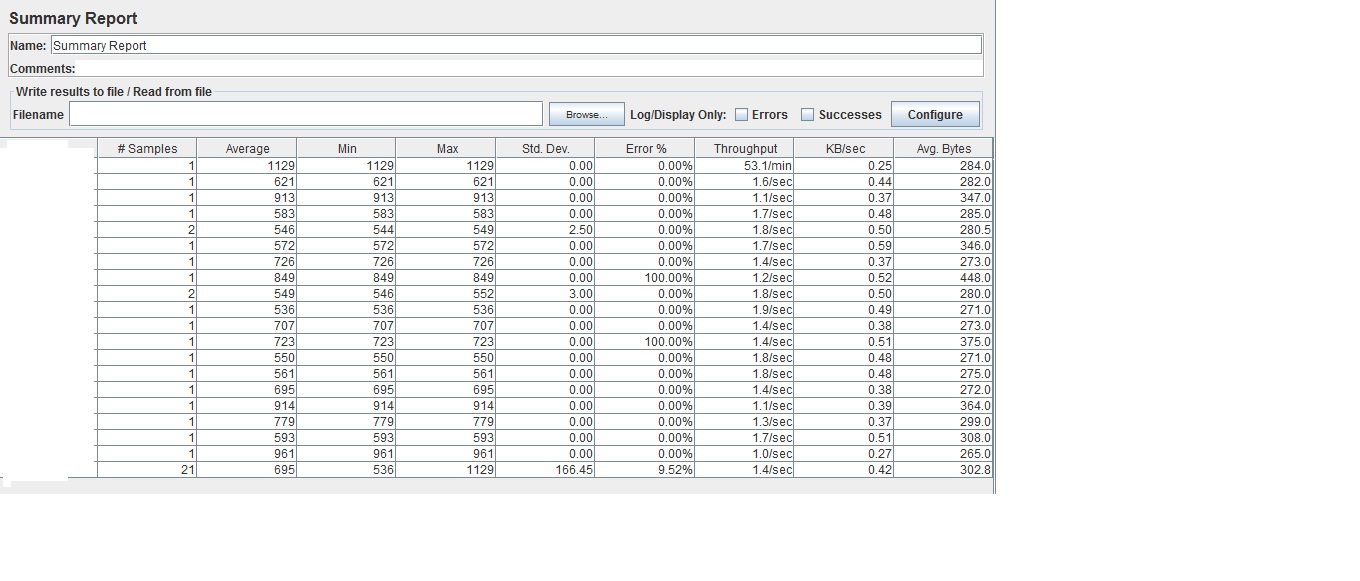
请帮助我了解JMeter是如何计算吞吐量值的:例如,第一行的吞吐量53.1/min,JMeter是如何使用哪个公式计算这个数字的。
另外,我想知道后续测试中的吞吐量值如何划分为分钟或秒。示例第二行的吞吐量1.6/秒,那么JMeter如何基于时间单位计算该吞吐量值?
在网上尝试了许多网站,得到了一个常见的答复,即吞吐量是在测试期间发送到服务器的每单位时间(秒、分钟、小时)的请求数。但这不适用于我在图表中看到的结果,因为它是直接解释的。
文档将吞吐量定义为
请求/时间单位。从第一个样本开始到最后一个样本结束的时间计算。这包括采样之间的任何间隔,因为它应该代表服务器上的负载。公式为:吞吐量=(请求数)/(总时间)。
所以在你的例子中,你有一个请求,需要1129毫秒,所以
Throughput = 1 / 1129ms = 0.00088573959/ms
= 0.00088573959 * 1000/sec = 0.88573959/sec
= 0.88573959 * 60/min = 53.1443754/min, rounded to 53.1/min
对于1次请求的总时间(或经过的时间)与此单次操作的时间相同。对于多次执行的请求,它将等于
Throughput = (number of requests) / (average * number of requests) = 1 / average
例如,如果截图中的最后一行(有21个请求),它的平均值为695,因此吞吐量为:
Throughput = 1 / 695ms = 0.0014388489/ms = 1.4388489/sec, rounded to 1.4/sec
就单位(秒/分钟/小时)而言,摘要报告是这样做的:
这就是为什么有些值以秒为单位显示,有些以分钟为单位,有些可能以小时为单位。有些甚至可能值为0.0,这基本上意味着吞吐量
我已经有一段时间在处理这个问题了,下面是我必须做的事情,以使我的数字符合jmeter所说的
在csv文件中循环我的行,收集每个标签的最低开始时间,也获取最高(时间戳经过的时间)计算这些之间的差异,然后做样本数量/差异
所以在excel中,最简单的方法是获取csv文件,并为已过的时间戳添加一列首先按时间戳对块进行排序——从最低到最高,然后对每个标签的第一个实例进行罚款,并获取时间,然后按新的排序列从最高到最低,并为每个标签再次抓取第一次
对于每个标签,然后将这两个时间都收集到一张新的表格中a将是标签B将是开始时间C将是结束时间D将是(C-B)1000(以秒为单位的差异)E将是每个标签的样本数F将是E/D(每秒样本数)G将是F60(每分钟样本数)
Throughput = NumOfRequests / ((endTime - startTime)*conversion)
endTime = lastSampleStartTime + lastSampleLoadTime
startTime = firstSampleStartTime
conversion = unit time conversion value
